集合
categories:
- 面试题
tags:
- Java
- 后端开发
date: 2023-02-27 19:26:00
集合
categories:
- 面试题
tags:
- Java
- 后端开发
date: 2023-02-27 19:26:00
集合
categories:
- 面试题
tags: [‘Java’,‘后端开发’]
date: 2023-02-27 19:26:00
# 集合概述
Java 集合,也是容器,构成于两个接口:Collection 和 Map 接口。用于存放键值对。
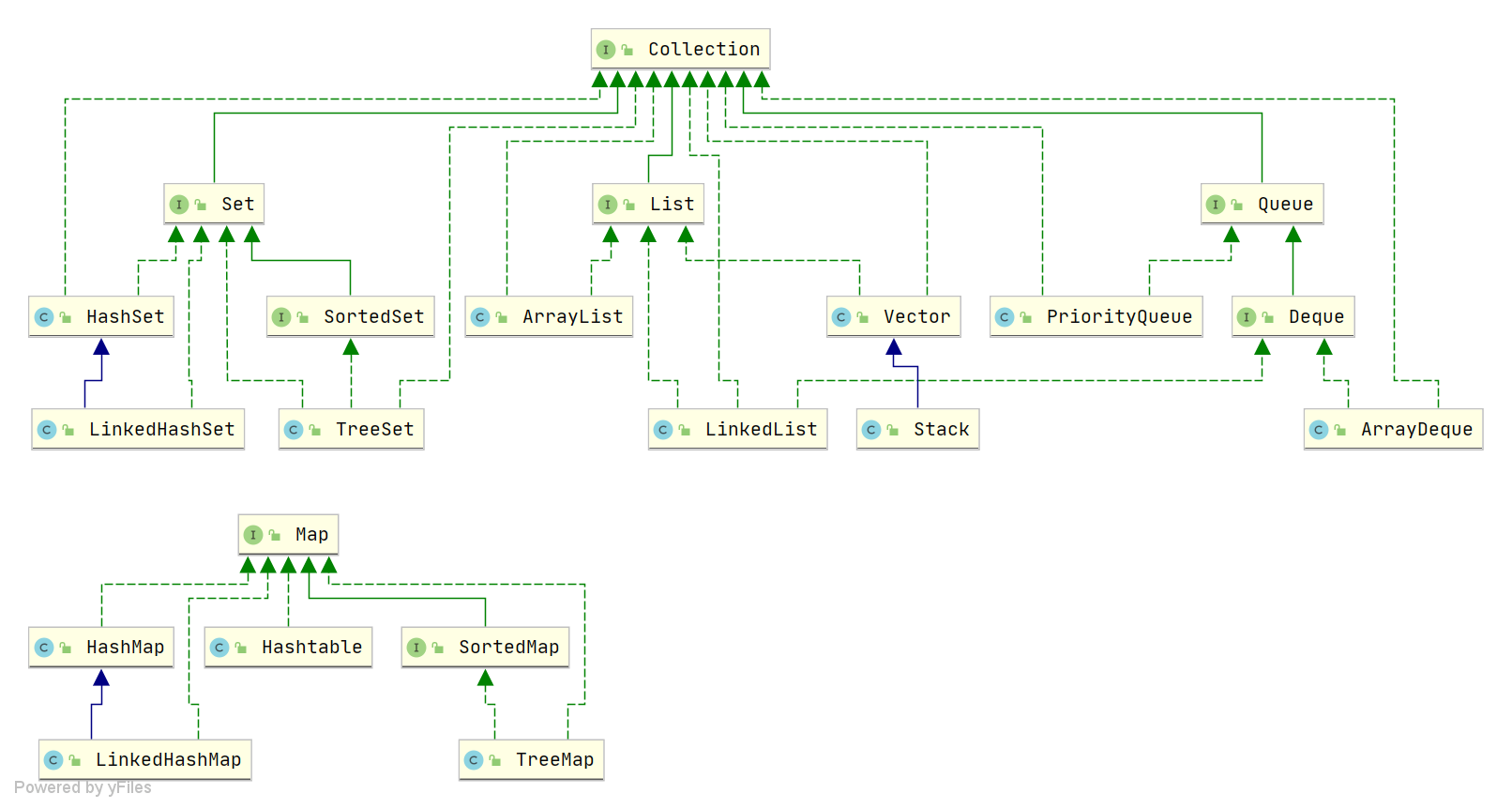
# 说说 List,Set,Queue,Map 四种集合的区别。
- List 比较适合存储有序的、可以重复的元素
- Set 常用于存储无序的、不可重复的元素
- Queue 按照特定的排队规则来确定先后顺序,存储的元素是有序的且可以重复
- Map 查询比较快,其中 key 无序且不重复,value 无序但可重复,一个键 key 对应一个 value 值
# 跟着视频复习一遍吧
韩顺平视频地址(https://www.bilibili.com/video/BV1YA411T76k/?spm_id_from=333.337.search-card.all.click&vd_source=7c6c7bb18c7ca81e3c9e3e6722861c9d)
主要的两大类,需要背
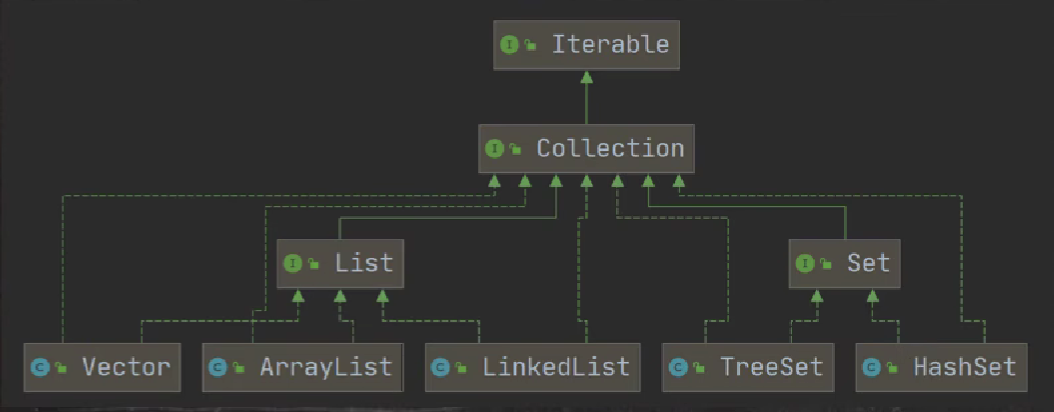
# List 接口的三种实现方法
LinkedList,ArrayList,Vector。
# List 的三种输出方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| package com.jun.List_;
import java.util.ArrayList;
import java.util.Iterator;
public class ListFor {
@SuppressWarnings("all")
public static void main(String[] args) {
ArrayList list = new ArrayList();
for (int i = 0; i < 12; i++) {
list.add("jun"+i);
}
System.out.println(list);
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("迭代器输出:"+next);
}
for (Object j :
list) {
System.out.println("增强for输出:"+j);
}
for (int i = 0; i < list.size(); i++) {
System.out.println("常规for输出:"+list.get(i));
}
}
}
|
# ArrayList 是线程不安全的,因为没有添加 synchronized 互斥锁,线程之前会同时进行操作,会导致脏读,幻读,错读。
所以在多线程情况下就不要使用 ArrayList 了。
# ArrayList 底层结构和源码分析
1) ArrayList 中维护了一个 Object 类型的数组 elementData.
2) 当创建 ArrayList 对象时,如果使用的是无参构造器(即没有指明大小),则初始化 elementData 容量为 0,第一次添加,则扩容 elementData 为 10,如果需要再次扩容 elementData 就为 1.5 倍。
3) 如果使用的指定大小的构造器,初始的大小 elementData 容量为指定大小,如果需要再次扩容,则直接扩容 elementData 为 1.5 倍。
# Vector 底层结构和源码分析
还是 List 接口的实现子类。
1) 底层也是一个对象数组。
2) 是线程同步的,即线程安全。Vector 类的操作方法有 synchronized
3) 在开发的过程中,需要考虑到线程同步安全问题时,可以考虑使用 Vector。
# LinkedList 底层结构和源码分析
1) LinkedList 底层实现了双向链表和双端队列特点
2) 可以添加任意元素(元素可以重复),包括 null
3) 线程不安全,没有实现同步。
😂
# 双向链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| package com.jun.List_;
public class LinkedList01_ {
public static void main(String[] args) {
node jack = new node("jack");
node tom = new node("tom");
node jun = new node("jun");
jack.next = tom;
tom.next = jun;
jun.pre = tom;
tom.pre = jack;
node first = jack;
node last = jun;
System.out.println("从头到尾遍历");
while (true) {
if (first == null) {
break;
}
System.out.println(first);
first = first.next;
}
System.out.println("从尾到头遍历");
while (true) {
if (last == null) {
break;
}
System.out.println(last);
last = last.pre;
}
}
}
class node{
public Object item;
public node next;
public node pre;
public node(Object name){
this.item = name;
}
@Override
public String toString() {
return "node name" + item;
}
}
|
# ArrayList 和 LinkedList 比较
ArrayList 和 LinkedList 的比较:
ArrayList 是可变数组,增删的效率比较低,数组可以扩容,改查的效率也比较高
LinkedList 是双向链表,通过链表追加,改查的效率比较低。
# Set 接口
主要的两个子实现类:HashSet 和 TreeSet
1)接口无序:添加和取出的顺序不一致,没有索引
2)不允许重复元素,最多包含一个 null
3)JDK API 中 Set 接口的实现类有 AbstractSet , ConcurrentHashMap.KeySetView , ConcurrentSkipListSet , CopyOnWriteArraySet , EnumSet , HashSet , JobStateReasons , LinkedHashSet , TreeSet
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| package com.jun.Set;
import java.util.HashSet;
public class SetMethod {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("john");
set.add("lucy");
set.add("jun");
set.add("jack");
set.add(null);
set.add(null);
System.out.println(set);
}
}
|
遍历方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println(obj);
}
for (Object o :
set) {
System.out.println(o);
}
|
# HashSet
1) 实现了 Set 接口
2) 实际上是 HashMap
3) 可以存放 null 值,但是只有一个 null
4) 不保证有序,即,不保证存放元素的顺序和取出的顺序一致。
5) 不重复的元素。
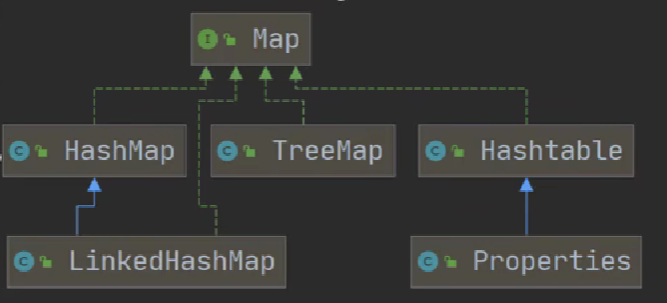
# Map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| package com.jun.map_;
import java.util.HashMap;
import java.util.Map;
public class Map_ {
public static void main(String[] args) {
Map map = new HashMap();
map.put("no1","jun");
map.put("no2","lili");
map.put("no1","zhang");
map.put("no3","lili");
map.put(null,null);
map.put(new Object(),"人人");
System.out.println(map);
}
}
|
# 开发中如何选择集合实现类
选择什么集合实现类,主要取决于业务操作特点:
1) 先判断存储的类型(一组对象 [单列] 或者一组键值对 [双列])
2) 一组对象:collection 接口
允许重复:list
增删多:LinkedList(底层维护了一个双向链表)
不允许重复:Set
无序:HashSet
排序:TreeSet
3) 一组键值对:Map
键无序:HashMap(哈希表,jdk7:数组 + 链表,jdk8:数组 + 链表 + 红黑树)
键排序:TreeMap
键插入和取出一致:LinkedHashMap
读取文件:properties
# Collections 工具类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| package com.jun.collection_;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
@SuppressWarnings({"all"})
public class Collections_tool {
public static void main(String[] args) {
List list = new ArrayList();
list.add("jun01");
list.add("jun02");
list.add("jun03");
list.add("jun04");
Collections.reverse(list);
System.out.println(list);
Collections.shuffle(list);
System.out.println(list);
Collections.sort(list);
System.out.println(list);
Collections.swap(list,0,1);
System.out.println(list);
System.out.println(Collections.max(list));
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String) o2).length();
}
});
System.out.println(maxObject);
}
}
|
脑瓜子痛

