
MySql复习
SQL 程序语言有四种类型,对数据库的基本操作都属于这四类,它们分别为;数据定义语言 (DDL)、数据查询语言(DQL)、数据操纵语言(DML)、数据控制语言(DCL)
# DDL 全称是 Data Definition Language,即数据定义语言
主要是实现
查询语句:
1 | CREATE TABLE users( |
# alter 修改
修改表名
1 | alter table users rename user_info; |
添加字段
1 | alter table user_info add testAlter varchar(20) not null; |
# 数据库设计规范
以下规则只针对本模块,更全面的文档参考《阿里巴巴 Java 开发手册》:
1、库名与应用名称尽量一致
2、表名、字段名必须使用小写字母或数字,禁止出现数字开头,
3、表名不使用复数名词
4、表的命名最好是加上 “业务名称_表的作用”。如,edu_teacher
5、表必备三字段:id, gmt_create, gmt_modified
说明:
其中 id 必为主键,类型为 bigint unsigned、单表时自增、步长为 1。
(如果使用分库分表集群部署,则 id 类型为 verchar,非自增,业务中使用分布式 id 生成器)
gmt_create, gmt_modified 的类型均为 datetime 类型,前者现在时表示主动创建,后者过去分词表示被 动更新。
6、单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。 说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
7、表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型是 unsigned tinyint (1 表示是,0 表示否)。
说明:任何字段如果为非负数,必须是 unsigned。
注意:POJO 类中的任何布尔类型的变量,都不要加 is 前缀。数据库表示是与否的值,使用 tinyint 类型,坚持 is_xxx 的 命名方式是为了明确其取值含义与取值范围。
正例:表达逻辑删除的字段名 is_deleted,1 表示删除,0 表示未删除。
8、小数类型为 decimal,禁止使用 float 和 double。 说明:float 和 double 在存储的时候,存在精度损失的问题,很可能在值的比较时,得到不 正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数分开存储。
9、如果存储的字符串长度几乎相等,使用 char 定长字符串类型。
10、varchar 是可变长字符串,不预先分配存储空间,长度不要超过 5000,如果存储长度大于此值,定义字段类型为 text,独立出来一张表,用主键来对应,避免影响其它字段索 引效率。
11、唯一索引名为 uk_字段名;普通索引名则为 idx_字段名。
说明:uk_ 即 unique key;idx_ 即 index 的简称
12、不得使用外键与级联,一切外键概念必须在应用层解决。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
# sql 语句左外连接 右外连接 内连接 全连接区别
内连接
内连接只返回两个表中共有且满足 ON 条件的行。即只有符合连接条件的数据才会被保留下来,不满足条件的被过滤掉。在执行 SELECT 语句时,如果没有指定任何 JOIN 类型,则会默认选择进行内连接。
1 | SELECT * |
左外连接
左外连接会返回左表中所有行以及与右表中匹配的行。如果右表中没有匹配的行,那么就产生空值 NULL。因此,左外连接返回的结果集包含了左表的所有数据以及左右表之间匹配的数据。如果右表中有多行符合 JOIN 条件,左表中的每一行都会被重复输出。
1 | SELECT * |
右外连接
右外连接与左外连接基本相同,但是查询的针对的表是右表(tableB)。右外连接会返回右表中的所有行以及与左表中匹配的行。如果左表中没有匹配的行,则左边显示空值 NULL。右外连接是左外连接的镜像,只是将左右表交换而已。
1 | SELECT * |
全连接
全连接是左右外连接的结合版。它会返回两个表中所有的数据行并进行匹配。如果某一个表中没有匹配的值,那么将补充 NULL 值。因此,结果集包含了两个表中所有的行。
1 | SELECT * |
# 示例
假设有两个表:表 A 和表 B。表 A 中有字段 id 和 name,表 B 中有字段 id 和 age,数据如下:
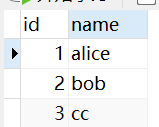
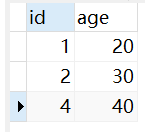
# 内连接
内连接会返回两个表中共有的行,即满足 JOIN 条件的行。
1 | SELECT * |
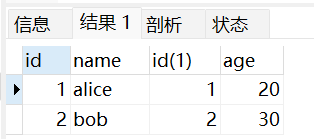
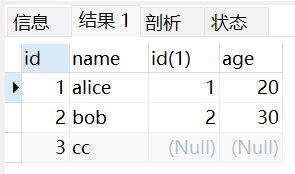
# 左外连接
左外连接会返回左表中所有的行,以及与右表中匹配的行。如果右表中没有匹配的行,则会用 NULL 填充。
1 | SELECT * |
# 右外连接
右外连接会返回右表中所有的行,以及与左表中匹配的行。如果左表中没有匹配的行,则会用 NULL 填充。
1 | SELECT * |
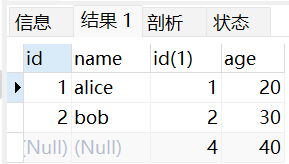
# 全连接
全连接返回两个表中所有的行,如果某一个表中没有匹配的行,则会用 NULL 填充。
1 | SELECT * |