
运维
# 运维的分类
单单从工作内容区分,运维有如下几类:
IDC 机房运维
桌面运维
监控运维
实施运维
系统运维
自动化运维
运维开发
数据库运维
大数据运维
DevOps 运维
IDC 机房运维:
目前薪资低,工作内容简单,而且未来可能会被人工智能替代的就是 IDC 机房运维
IDC 机房运维的工作主要包括:主机监控,信息统计,硬件维护,系统维护,网络维护。比如对托管设备进行日常的巡检,故障记录;协助客户对 IDC 机房设备进行维护等等。
很多 IDC 机房运维,后期都转型做销售岗,还有的考了几个证书后,转到大公司做运维了
这是一个钱少,活杂,上升渠道少的岗位,未来发展靠个人。北大的保安也能考研究生成为网红,只要努力还有什么不可能呢。
三年工作经验:薪资 5-9K,有的公司需要倒班。
售前运维
在产品的销售过程中,一般会有这个岗位存在,毕竟销售人员对技术能力的掌握都有所欠缺,如果客户问到技术上的问题,就需要售前运维出场。
售前运维:对技术要懂一些,对销售也懂一些。所以售前运维的未来发展方向有两个,一个是往技术方面发展,一个是往销售方面发展。而且曾经的销售经验决定大大提高了自己往技术方向发展的概率。毕竟各行各业都需要沟通,运维行业更得懂得沟通。
一个一年左右的售前运维,薪资在一万以上很常见。但希望大家把这个岗位作为一个过渡,一心不能两用,很难做到既搞好销售,又能做好技术。如果你可以,建议你去创业,一个技术创业者,既要懂技术,又要懂销售。
桌面运维
桌面运维目前属于外包的比较多,有专门的公司招聘应届生去培训一两个月,直接外派到大公司做项目,需要的技能不是很多,但是沟通能力很重要,之所以要沟通能力,只因为你是乙方,说白了就是去人家家里干活的,属于服务行业。
要做的事情很杂:比如 OA 加载不了 PDF 怎么办?又或者网络 IP 重名,还有诸如电脑没有声音,word 插入不了大写字母,打印机出现了故障,投影仪不能使用,需要装装系统等等
工作重复性很高,只要你用过几年电脑(你自己的笔记本),基本上都可以干运维,如果你擅于用百度,那公司里大部分业务跟桌面终端问题,你都可以搞得定。
工作比较清闲,薪资不高,很多人的薪资一直停留在 8k 左右,如果不努力提高自己,被替代的可能性很大,随便一个大学生,入职三个月就能干你的活。
而且桌面运维看重学历,现在要求本科学历的越来越多,对英语的要求也越来越高。
未来的桌面运维,一定是要求越来越高,比如学历,比如口语流利程度,但工资会越来越低。
实施运维
一个需要频繁出差的岗位,有的公司实施运维的工作里还穿插了售前运维的工作,公司的产品需要涉及到去客户公司部署产品以及后期的跟进维护,举个安装移动宽带的例子吧, 实施运维就是前期去你家安装网线,并调试好,直到你能上网,后期对你的网络进行维护。这个工作涉及到的技术比较单一,或者说都是与你们产品有关的技术,比如你们公司是做私有云的,你需要满世界去帮别的公司部署私有云产品和后期维护
需要有一定的沟通能力,技术增长一般是体现在对你们公司产品越来越了解,
如果你想去看看世界(真心话,大多数实施运维忙的没时间看世界),或者不反感出差,也不怕与人交流,可以选择这个职位,3 年工作经验,薪资在 12-15K 左右
系统运维和自动化运维
这两个相似度很高,一度可以这么理解:自动化运维就是在系统运维的基础上又学会了一些自动化工具,比如 ansible, saltstack,shell 脚本, 系统运维到自动化运维,是传统运维向智能运维的过渡。
一般情况下,系统运维的工资,三年工作经验在 8-10K, 自动化运维可以达到 10-15K, 需要会一些常见的 ELK,jenkins,gitlab, docker 等工具。
这里需要着重强调的两个概念:
所有自动化运维都是以手工能实现为基础。
所有自动化的底层,都是很基础浅显的原理。比如监控系统, 不管你用 zabbix, 还是 prometheus, 还是自己开发监控,说到底都是在做数据收集,数据存储,数据分析和数据展示。
运维开发
不会开发你就不能充分理解你们系统的业务流程,出了问题也不能帮忙调试,只能去找开发推锅,开发人员写的代码有时候有性能问题,而你只却只懂系统,就没办法排查问题,或者说没办法找到问题根本原因。
运维开发需要学什么开发语言?理论上小语种都行,而不是说到运维开发就想到 python,那只是培训机构的人设。
三年运维开发经验,工资一般在 12-18K 左右。
另外需要说明,开发语言只是工具,帮助你解决工作中的问题,而不是动不动就开发个 CMDB,开发个跳板机。在公司里工作,有开源的就用开源的,实在没办法了才去开发。不要给自己挖坑
备注:即使你面试的是运维开发,很多时候你在公司里干的还是系统运维或者自动化运维的工作,与开发没有任何关系,而且大部分公司现有的业务体系的服务器都老出问题,你忙都忙不过来,哪还有时间让你开发自动化工具, 如果让你白天不耽误干别的,利用晚上自己加班搞出来,方法方案自己想办法,加班费是不可能又的,你干吗?不想干就别提这个茬,做好公司交代的任务就行了。
数据库运维
哈,刚刚一个运维开发还不够乱吗,又来个数据库运维,说白了就是有的公司让系统运维兼职干着数据库的工作,干久了就出来这么个岗位,懂运维,懂数据库。
现在很多人面试系统运维,都说自己懂数据库,结果一问,数据库只会增删改查,再一问增删改查也是只会最简单的,说白了就是记住了增删改查的四个命令而已,真香。
很多时候运维遇到的问题不像你想象的那么理想化,比如有同事过来求助,说一个单机实例挂了。你的理想状态是,反正有备份,恢复一下完事。然后你问他,有备份吧?
对方说:“不知道啊,跑了好几年了没出过问题,你一入职就出问题了”
哈,关键是你刚入职,入职手续还没办完,都没碰过公司的电脑。你说惊不惊喜。
数据库玩的比较好,以后可以转 DBA,但只会 DBA 不会运维的人,可能慢慢要没落了,这个岗位就是运维在绝地逢生,不断占领别人的岗位的过程中演化出来的岗位,当然也有可能是 DBA 学会了运维。
大数据运维
大数据运维也是在系统运维的基础上衍生出来的一种,与系统运维不同的是,大数据运维更多的是在维护大数据生态下的产品,比如 Hadoop,Hbase,Spark,Kafka ,Redis 等,进行日常的集群管理和故障处理,以及容量管理。
基础的系统运维要会,在此基础上加上大数据生态圈下的产品就是算入门的大数据运维了
薪资也偏高一些,一般三年工作经验可以要到 12-20k, 为什么有 8K 的差距呢?因为面试看的是沟通能力,和技术关系不大。
DevOps 运维
DevOps 是一种方法论,包含一系列的基本原则和实践,目前所有的工具或者说工具链都只是为了对这样的实践提供支持而已。
所以这个岗位,其实都是要求在自动化运维的基础上,会一些 DevOps 工具链而已,比如 CI/CD 的开源工具。
其次要想工资高,需要会一门语言,比如 go 或者 python。
薪资普遍很高,三年工作经验,基本在 15-20K,5 年工作经验可以拿到 30-50K。
后续:
如果你想往运维方向发展,首先要成为系统运维,然后再慢慢向自动化运维发展。等薪资达到 12K-15K 后,再考虑往哪个方向发展,这些岗位不存在哪个更有前途,因为前途这件事,靠个人,靠运气,靠机遇。
# LNMP 工作流程
LNMP 是一种常见的服务器架构,由 Linux、Nginx、MySQL 和 PHP 组成。下面是 LNMP 的一般工作流程:
-
客户端发送请求:用户通过浏览器或其他客户端向服务器发送 HTTP 请求。
-
Nginx 接收请求:Nginx 作为 Web 服务器软件,接收到客户端发送的请求。Nginx 可以处理大量并发连接,并具有性能优化特性。
-
静态文件处理:如果请求的是静态文件(例如 HTML、CSS、JavaScript、图像等),Nginx 可以直接返回这些文件给客户端,无需进一步处理。
-
动态请求转发:如果请求需要动态处理(例如通过 PHP 生成动态内容),Nginx 将把请求转发给后端的 PHP 解释器。
-
PHP 处理请求:PHP 解释器接收到来自 Nginx 的请求,并执行相应的 PHP 脚本。脚本可以与数据库进行交互、处理逻辑、生成动态内容等。
-
数据库查询:如果 PHP 脚本需要从数据库中读取数据,它会使用 MySQL 客户端连接到 MySQL 数据库,并执行相应的 SQL 查询操作。
-
数据处理与模板渲染:PHP 脚本根据业务逻辑处理数据,并将结果传递给模板引擎。模板引擎可以将数据填充到预定义的模板中,并生成最终的动态内容。
-
响应返回客户端:PHP 脚本将生成的动态内容返回给 Nginx,然后 Nginx 再将其发送给客户端作为 HTTP 响应。
-
客户端呈现响应:客户端(浏览器)接收到服务器返回的响应,并根据响应的内容进行渲染和显示。
LNMP 架构通过将不同的组件相互配合工作,实现了高性能的 Web 服务。Linux 提供稳定可靠的操作系统环境,Nginx 作为前端 Web 服务器处理请求并转发给后端的 PHP 解释器,PHP 与 MySQL 协同工作来处理动态内容和数据库查询,最终将结果返回给客户端。
# LAMP
LAMP 是一种常见的服务器架构,由 Linux、Apache、MySQL 和 PHP 组成。下面是 LAMP 的一般工作流程:
-
客户端发送请求:用户通过浏览器或其他客户端向服务器发送 HTTP 请求。
-
Apache 接收请求:Apache 作为 Web 服务器软件,接收到客户端发送的请求。Apache 可以处理大量并发连接,并具有灵活的配置选项。
-
静态文件处理:如果请求的是静态文件(例如 HTML、CSS、JavaScript、图像等),Apache 可以直接返回这些文件给客户端,无需进一步处理。
-
动态请求转发:如果请求需要动态处理(例如通过 PHP 生成动态内容),Apache 将把请求转发给后端的 PHP 解释器。
-
PHP 处理请求:PHP 解释器接收到来自 Apache 的请求,并执行相应的 PHP 脚本。脚本可以与数据库进行交互、处理逻辑、生成动态内容等。
-
数据库查询:如果 PHP 脚本需要从数据库中读取数据,它会使用 MySQL 客户端连接到 MySQL 数据库,并执行相应的 SQL 查询操作。
-
数据处理与模板渲染:PHP 脚本根据业务逻辑处理数据,并将结果传递给模板引擎。模板引擎可以将数据填充到预定义的模板中,并生成最终的动态内容。
-
响应返回客户端:PHP 脚本将生成的动态内容返回给 Apache,然后 Apache 再将其发送给客户端作为 HTTP 响应。
-
客户端呈现响应:客户端(浏览器)接收到服务器返回的响应,并根据响应的内容进行渲染和显示。
LAMP 架构通过将不同的组件相互配合工作,实现了搭建和运行动态网站所需的环境。Linux 提供稳定可靠的操作系统环境,Apache 作为前端 Web 服务器处理请求并转发给后端的 PHP 解释器,PHP 与 MySQL 协同工作来处理动态内容和数据库查询,最终将结果返回给客户端。
# shell
shell 编写一个脚本:进行重要文件的归档备份。
重点部分:
- 网络配置
- 权限管理和用户管理
- 磁盘管理查看和进程管理
# kafka 学习
# 生产者
查看操作生产者的命令参数
1 | bin/kafka-console-producer.sh |
发送消息
1 | bin/kafka-console-producer.sh --bootstrap-server hadoop01:9092 --topic first |
# 消费者
# Hadoop 实战
大数据应用场景
采取 MapReduce 分而治之的策略
不拆分的计算任务或相互间有依赖关系的数据无法进行并行计算
# MapReduce
借鉴了函数式的思想,通过 Map 和 Reduce 的两个函数提供了高层的并行编程抽象模型
map:对一组数据元素进行某种重复式的处理
Reduce:对 Map 的中间结果进行某种进一步的结果整理。
主要应用在离线计算框架,在实时领域不行,就是无法进行流式数据的计算
# WordCount 经典实现
map 阶段的核心:把输入的数据经过切割,全部标记为 1,因此输出就是 <单词,1>
shuffle 阶段核心:经过 MR 程序内部自带的默认的排序分租等功能,把 key 相同的单词会作为一组数据构成新的 kv 对
reduce 阶段核心:处理 shuffle 完的一组数据,该组数据就是该单词所有的键值对。对所有的 1 进行累加求和,就是单词的总次数。
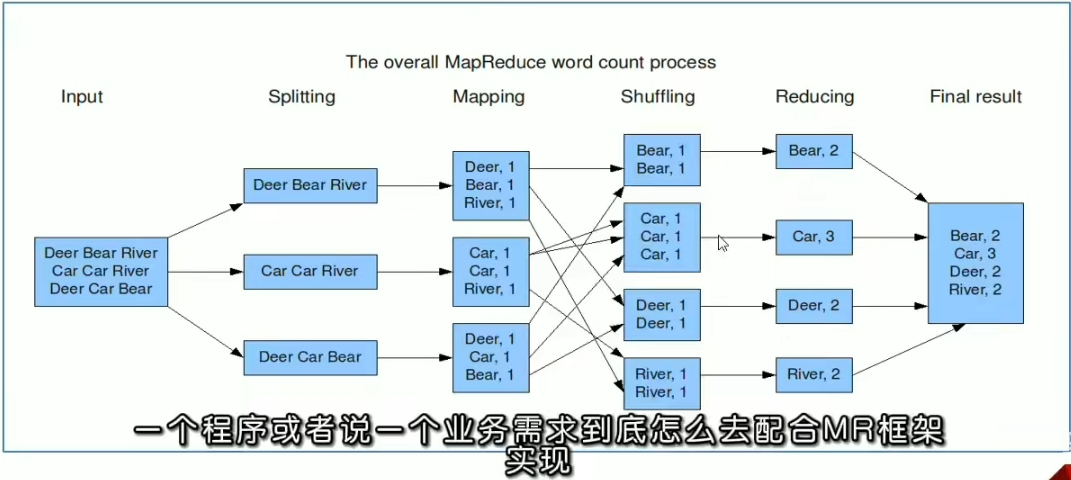
input ----》 Splitting ------》 Mapping ------》Shuffling -----》 Reducing ------》 Final Result
# shuffle 概念
Shuffle 的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据
而在 MapReduce 中,Shuffle 更像是洗牌的逆过程,指的是将 map 端的无规则输出按指定的规则 “打乱” 成为具体的有一定规则的数据,以便 reduce 端接收处理。
Map 产生输出开始到 Redecue 取得数据作为输入之前的过程叫做 shuffle
(简单理解就是无序到有序的过程)
# YARN 简介
yarn 是一个通用的资源管理系统和调度平台
资源管理系统:内存、CPU
调度平台: 资源怎么分配?(调度算法)
# YARN 三大组件
ResourceManager(RM)
YARN 集群中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终仲裁者。接收用户的作业提交,并通过 NM 分配、管理各个机器上的计算资源
NodeManager(NM)
YARN 中的从角色,一台机器上一个负责管理本机器上的计算资源
ApplicationMaster(AM)
用户提交的每个应用程序均包含一个 AM
应用程序内的 “老大”,负责程序内部各阶段的资源申请,监督程序的执行情况。
# Hive
# 数据仓库
如数仓是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境,
这种面向分析、支持分析的系统称为 OLAP(联机分析处理)系统。
Hive 是一款建立在 Hadoop 之上的开源数据仓库系统,可以将存储在 Hadoop 文件中的结构化、半结构化数据映射为一张数据库表,基于表提供了一种类似 SQL 的查询模型,称为 Hive 查询语言(HQL),用于访问和分析存储 Hadoop 中的大型数据集。
核心功能就是将 HQL 转化为 MapReduce 程序,然后将程序提交到 Hadoop 集群中执行。
Hive Driver 驱动程序
# 杂记
对字节进行输入操作一般继承为 InputStream
区别点:
InputStream 字节输入流
OutputStream 字节输出流
Reader 字符输入流
Writer 字符输出流